Основная моя деятельность уже много лет связана с фотографией, поэтому, блуждая по интернету, я обращаю внимание больше на оформление и иллюстрации чем на текст. Когда я наткнулся в интернете на снимки взрывов в Медео при строительстве плотины, мне показалось, что качество фотографий могло бы быть и лучше. Поиск по картинкам тоже не дал удовлетворительного результата: были найдены еще несколько фотографий, но и они были далеки до идеала, возможно, хорошие фотографии в сети и есть, но они настолько плохо документированы, что поисковик их не находит. Тогда я решил попытаться оцифровать и выложить то, что было в архиве отца. Это, в первую очередь, альбом формата А3 с наклеенными в него цветными фотографиями и несколько статей с практически теми же, но черно-белыми фотографиями, напечатанными офсетом. От цвета, правда, в фотографиях 1967 года осталось немного, да и не уверен, что изначально цвета на них были идеальными.
Но, попытка не пытка, и таким образом была поставлена задача оцифровать фотографии, оцифровать и распознать текст, вставить сопроводительный текст внутрь файлов с фотографиями. Я не собирался работать с большими объемами материалов и привлекать для этого профессиональную аппаратуру и программы. Хотелось лишь разобраться, есть ли возможность подручными средствами выполнить эту задачу и какая аппаратура и программы для этого лучше подходят.
Подручными средствами означало, что у меня в наличии лишь сканер в составе МФУ Samsung SCX 4200. Это сканер типа CIS, о недостатках этого типа сканеров я неоднократно писал, например, здесь. Кроме того у него монохромные линейки и цветное сканирование осуществляется за счет последовательной смены цвета подсветки, ну и наконец он только А4 причем стекло чуть утоплено ниже внешней рамки, что затрудняет возможность плотно прижать фотографию формата А3 к стеклу. Для работы с текстами его, естественно, более чем достаточно. В качестве альтернативы у меня было множество цифровых аппаратов, но пересъемка глянцевых фотографий это тоже не сахар - проблема бликов. Для обработки был компьютер и ноутбук оба с ОС Slackware. В первом случае с версией 13.37, а во втором 14.0. Для связи с МФУ был установлены, соответственно, Унифицированный Драйвер Самсунг 3.00.19 и 4.00.31.
Начать я решил со сканирования, решив, что будет более простым решением. Сперва сканируем по частям, потом в программе hugin
сшиваем. При сшивке сканированных частей нам не надо исправлять
искажения оптики, поэтому на вопрос о фокусном расстоянии объектива
выставляем максимальное значение. Я ставил 1000 мм.
Однако оказалось, что для выцветших фотографий число тонов, которые
способен передать данный сканер, явно недостаточно. Несмотря на то, что
обе половинки сканировались программой xSane при одинаковых режимах,
сшивка ситуацию усугубляла и полосы на плавных переходах бросались в
глаза. Динамического диапазона для спектра выцветших фотографий
катастрофически не хватало.
Съемка в сыром формате позволяет существенно увеличить число градаций, поэтому следующая попытка была произведена камерой Sony NEX-5 с объективом 16 мм. Поскольку в фотографиях впечатлял только формат, а не детализация фотографий, то я не пытался полностью использовать всю площадь матрицы и, чтобы избежать бликов, снимал под небольшим углом к перпендикуляру. Для преобразования из RAW, первичной цветокоррекции и исправления перспективных искажений использовалась программа DarkTable.
Для растровых черно-белых фотографий сканирование с разрешением 300 dpi и устранением растра средствами xSane было вполне достаточно.
Для распознавания безусловно лучшей программой сегодня является FineReader Engine, но 150 уе за лицензию на 12000 распознаваний в год - это явно не тот вариант, который можно назвать подручными средствами. Поэтому пришлось обратится к ее конкурентам 90 годов прошлого века и посмотреть, как они себя чувствуют сегодня.
Система оптического распознавания текстов CuneiForm разрабатывалась российской компанией Cognitive Technologies с 1993 года. Входила в состав пакета Corel Draw. В 1996 году в ней впервые в мире были применены алгоритмы адаптивного распознавания. Развивалась до 1999 года и, если рассматривать только алгоритмы оптического распознавания без предварительной обработки изображения и финишной лингвистической обработки, была, возможно, лучшей и до сих пор вполне себе ничего. В 2008 года были опубликованы исходные тексты OCR Cuneiform под лицензией BSD. Последняя версия Linux port of Cuneiform 1.1.0 вышла 19.04.11. Проект, похоже, заброшен.
Программа Tesseract разрабатывалась фирмой Hewlett-Packard с 1985 по 1998 годы, а затем была брошена до 2006 года, когда корпорация Google ее купила и открыла исходные тексты под лицензией Apache 2.0. В 90 годах она была нам не интересна, хотя и поставлялась часто вместе со сканерами, поскольку русский язык не поддерживался, сегодня с языком все в порядке и она не очень быстро, но развивается. Текущая стабильная версия 3.02 от 23.10.12 и 4 февраля 2014 года было объявлено о выходе V3.03 (rc1).
Хотя обе программы имеют только консольный интерфейс, для них разработано сторонними разработчиками несколько графических интерфейсов. Я попробовал поработать с двумя из них: YAGF и OCRFeeder. Выяснилось, что графические интерфейсы используют возможности консольных интерфейсов по-разному и не полностью. Поэтому результат зависит не только от программы распознавания, но и от графического интерфейса. Однозначно сказать, какая комбинация дает лучший результат, я не могу.
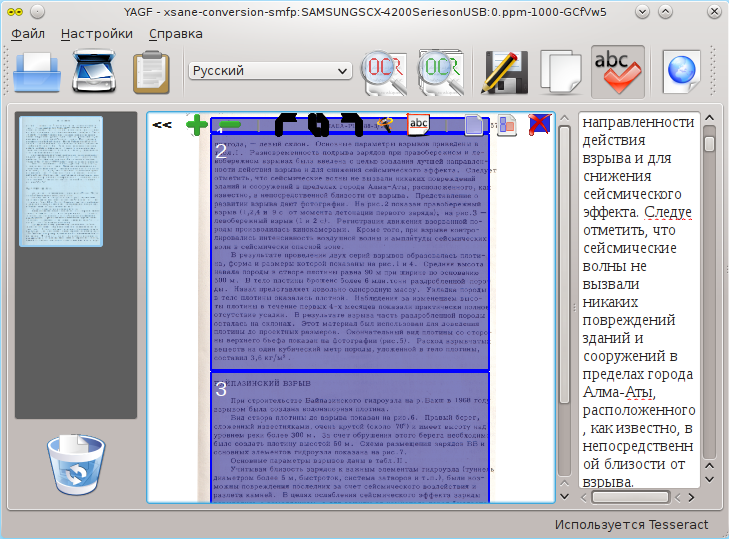
В плюсам YAGF можно отнести возможность повернуть загруженную страницу и работу со сканером через xSane, что дает более гибкие настройки сканирования.
OCRFeeder работает через Sane и не позволяет вмешаться в настройки сканирования.
Однако он может улучшать сканированное изображение с помощью модуля Unpaper. Оба графических интерфейса позволяют выравнивать слегка повернутые страницы.
К минусам YAGF я бы отнес то, что он не совсем корректно автоматически выделял блоки, обрезая выступающие на поля строчки. (В OCRFeeder этот эффект замечен не был. В обоих интерфейсах есть возможность выделять блоки вручную). Абзацы выделяются только при записи результата в HTML, причем только при распознавании через CuneiForm, при работе с Tesseract выделялись не абзацы а строки. Знаки переносов убираются только при работе с CuneiForm и записью в текстовом режиме. OCRFeeder с абзацами и переносами справлялся лучше вне зависимости от программы распознавания и записывал результат в файла ODT.
С таблицами мне не удалось справиться ни в одной комбинации программ и графических интерфейсов.
Программы распознавания предъявляют несколько разные требования к режимам сканирования. Т.е. наилучшее распознавание у них происходит при разном контрасте и разрешении сканирования. Для CuneiForm повышение разрешения свыше 200 dpi не приводит к улучшению качества распознавания.
Для качественных сканов результаты близкие, хотя могут быть не распознаны разные символы. Графические интерфейсы позволяют применять разные программы распознавания к отдельным абзацам, а также задавать язык. CuneiForm умеет работать со смешанным русско-английским текстом, а Tesseract нет, хотя последний сейчас поддерживает большее количество языков.
Итак, фотографии и текст к ним оцифрованы, теперь стоит задача соединить эти данные так, чтобы потом, даже если фотография вырвана из контекста статьи, можно было определить, что на ней изображено. Возможность вкладывать подписи в файл с фотографиями существует очень давно. Но есть большой риск, что прочитана эта подпись будет только той программой которой сделана. Но, ничто не вечно и весьма вероятно, что фотография переживет эту программу и OC, под которой она могла работать. Кроме того, для русского языка было придумано уж слишком много кодировок, и риск увидеть кракозябры очень велик. Сейчас ситуация стало несколько лучше, похоже что UTF-8 становится основным стандартом для всех. С полями для записей тоже стало больше единообразия. Можно выделить три основных стандарта: EXIF, IPTC, XMP.
EXIF (Exchangeable Image File Format) — стандарт, позволяющий добавлять к изображениям и прочим медиафайлам дополнительную информацию (метаданные), комментирующую этот файл, описывающую условия и способы его получения, авторство и т. п.
IPTC (International Press Telecommunications Council — Международный совет по прессе и телекоммуникациям) — стандарт метаданных для цифровых изображений, который позволяет хранить аннотацию, описывающую содержание. Изначально предполагалось использование только латиницы, и хотя сейчас многие программы позволяют записывать в поля IPTC текст, в разных кодировках вероятность того что, кириллица будет правильно прочитана всеми программами, достаточно низкая.
Adobe XMP (eXtensible Metadata Platform — расширяемая платформа метаданных) — это технология, созданная Adobe и позволяющая пользователю добавлять дополнительную информацию в файл.
Если создать подпись во всех этих стандартах, то вероятность, что ее можно будет просмотреть с самыми разными программами, резко повышается. Желательно вносить все записи одной программой, поскольку если это делать разными, то есть большой риск, что старые записи будут уничтожены. Я считаю самой подходящей для этой цели программой XnViewMP.
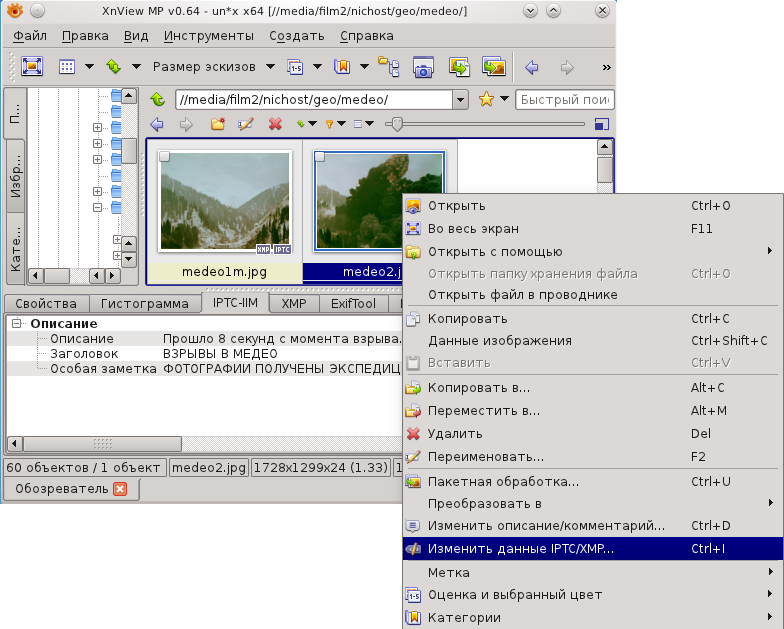
Чтобы записать данные, открываем меню Изменить описание/комментарий.
А затем меню Изменить данные IPTC/XMP.
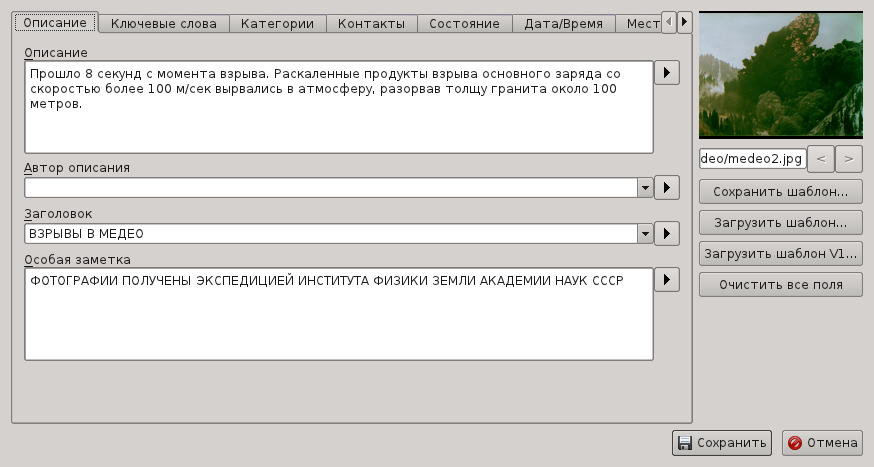
В результате, при просмотре мы будем видеть следующие записи:
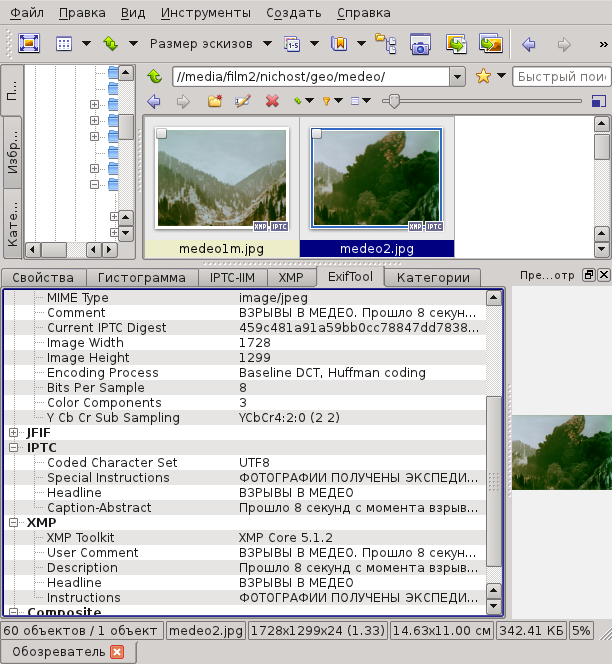
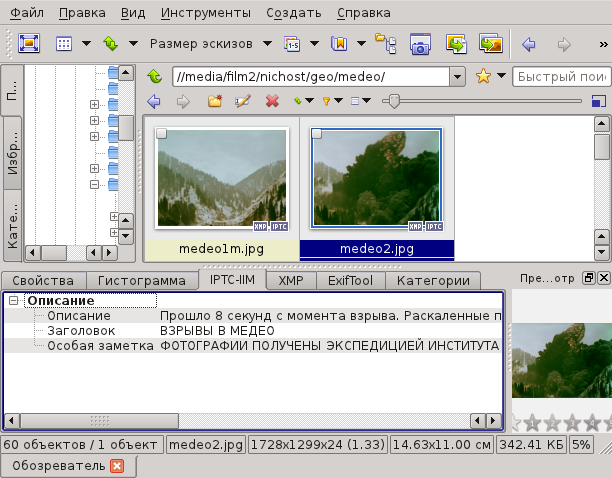
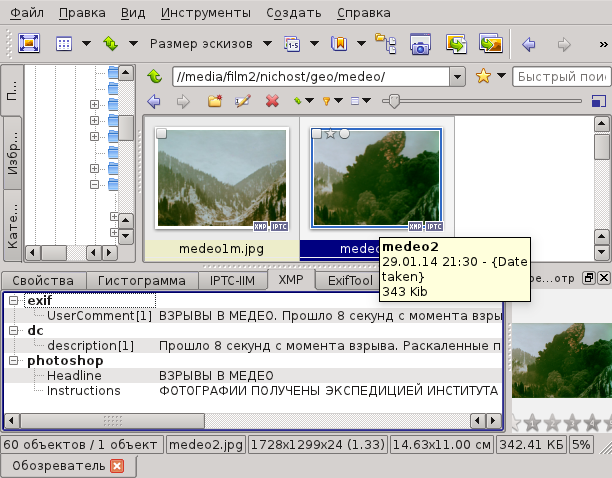
Главный аргумент в пользу этой программы это то что она мультиплатформенная и адекватно воспроизводит старые записи в самых разных кодировках. Есть надежда, что, как минимум, с ее помощью записи будут увидены и в других ОС.
А сейчас посмотрим, что из внесенных записей мы увидим в других программах под Linux.
В Geeqie Image Viewer информацию о файле можно посмотреть в боковой панели и отдельном окне Exif.
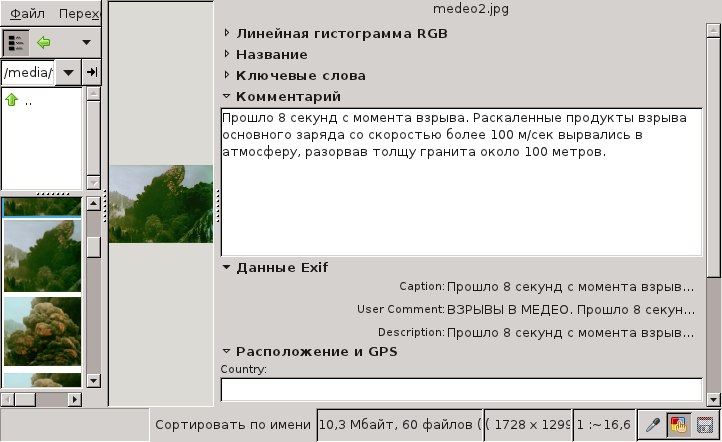
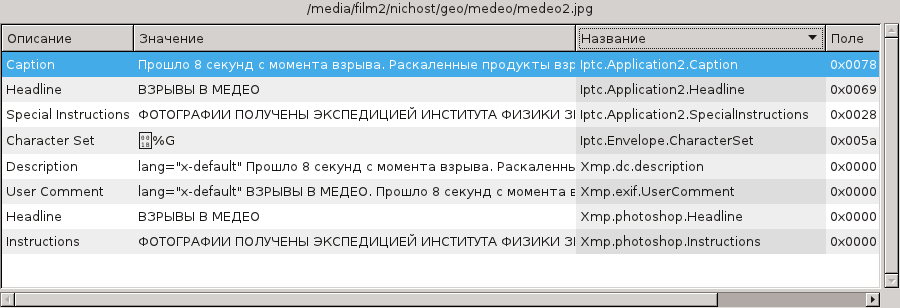
Результат прекрасный. Вся занесенная информация отображается.
В Fotoxx:
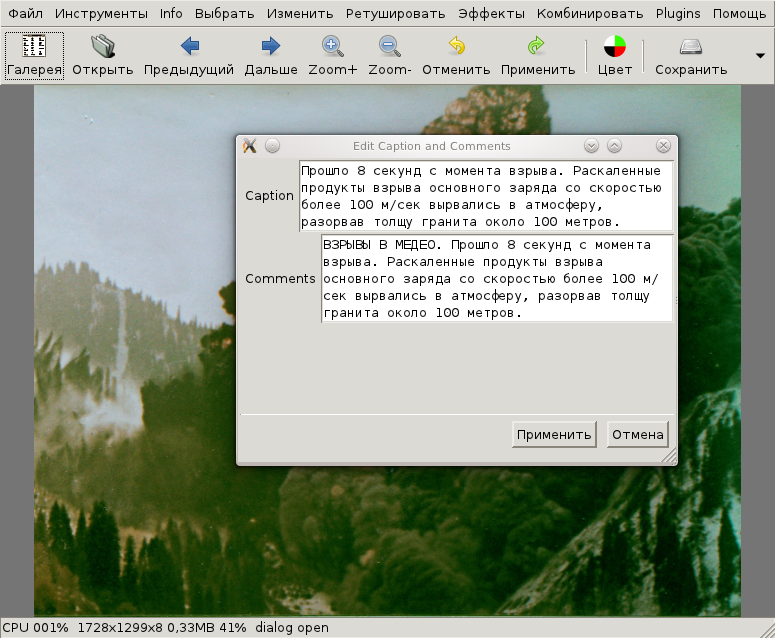
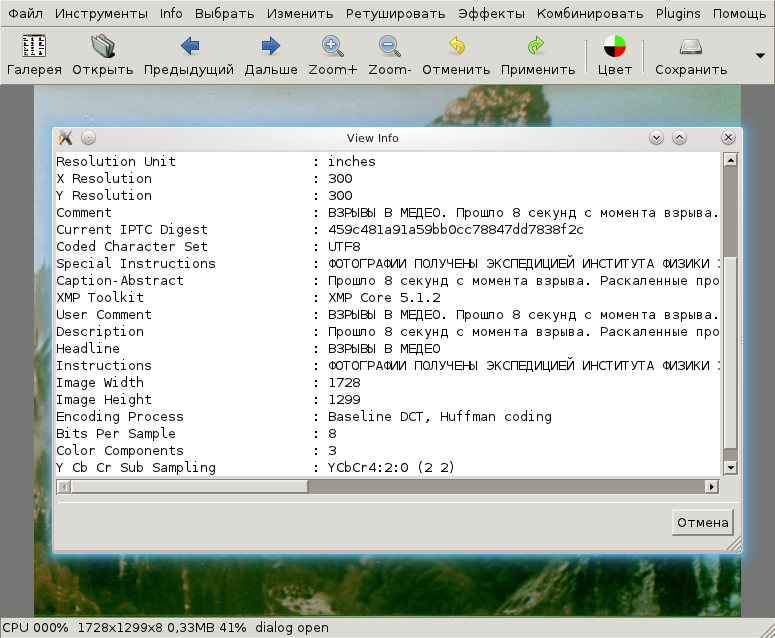
Результат прекрасный. Вся занесенная информация отображается.
showFoto:
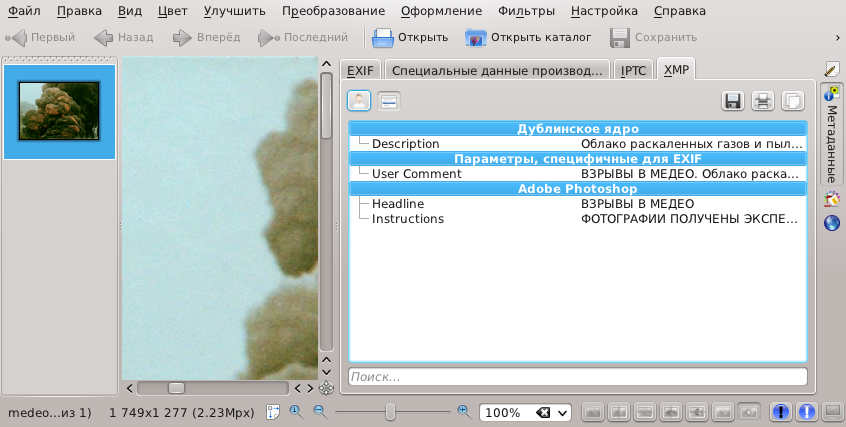
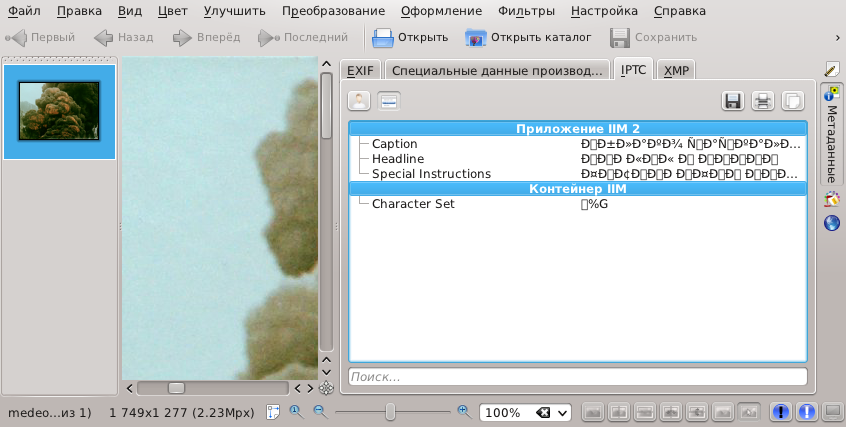
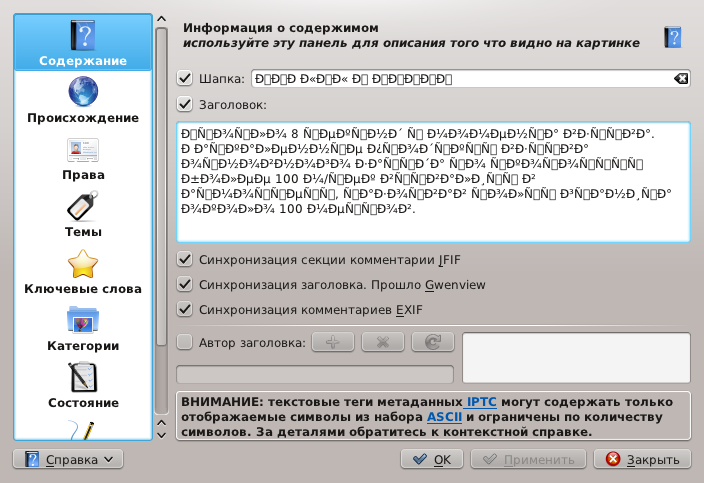
Здесь закладка XMP читаемая, а IPTC нет. Аналогичный результат и Gwenview, но там нам поясняют, что в соответствии со стандартом должно использоваться только ASCII.
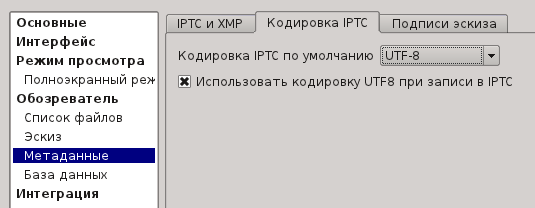
Я так и не понял, предложение в XnViewMP писать в UTF-8 это самодеятельность ExifTool или последняя версия IPTC действительно допускает такую возможность.
В заключение, даю ссылки на архивные фотографии Взрыва в Медео, работе с которыми была посвящена эта статья.